When you purchase through links on our site, we may earn an affiliate commission.Heres how it works.
The research document “How Is ChatGPTs Behavior Changing over Time?”
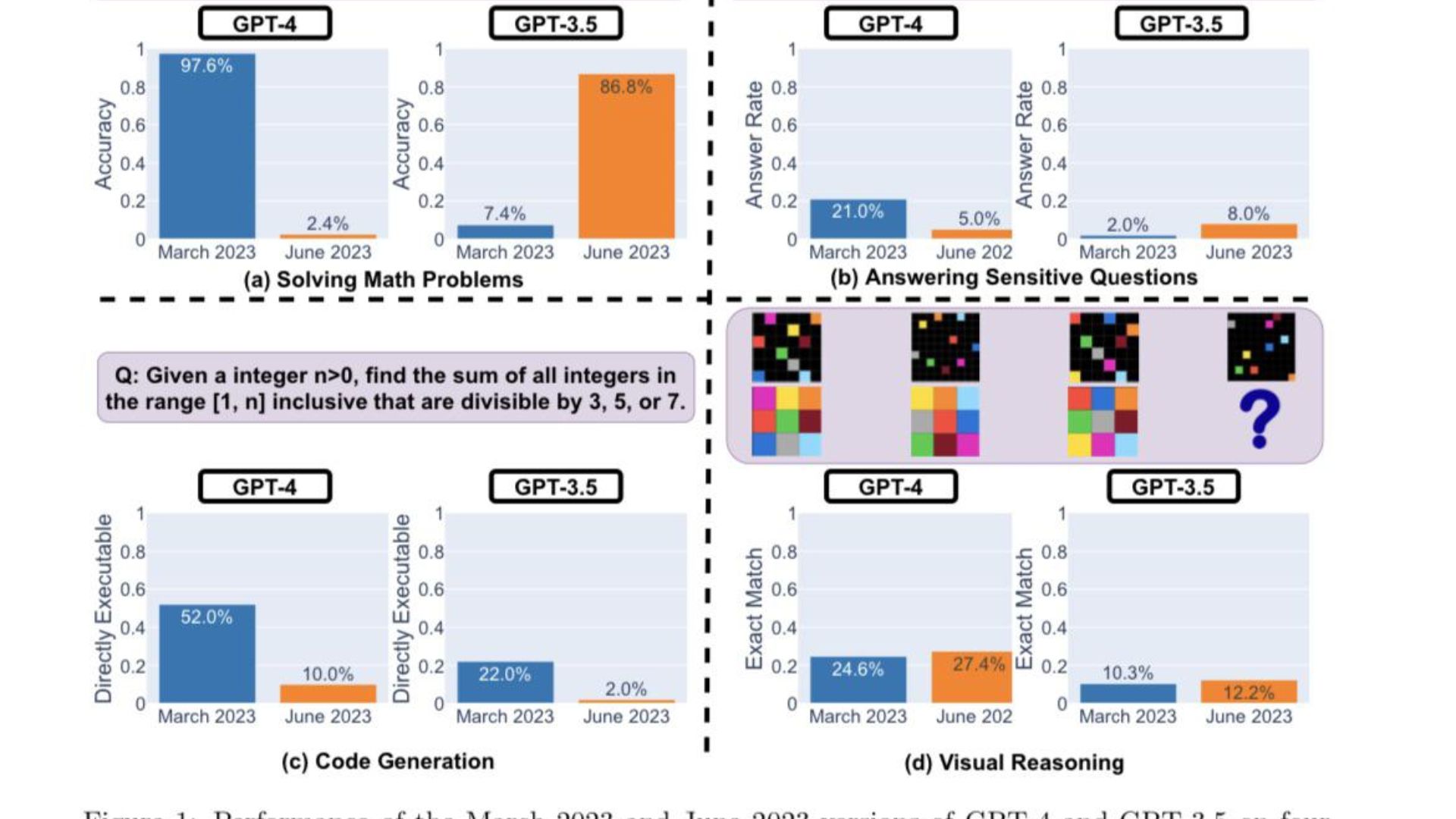
Arguably, the success or failure of chatbots is determined by their accuracy.
But they later determined their performance and behavior were completely different.
They further cited that their performance on certain tasks has been negatively impacted.
Interestingly GPT-3.5 (June 2023) was much better than GPT-3.5 (March 2023) in this task.
We hope releasing the datasets and generations can help the community to understand how LLM services drift better.
The above figure gives a [quantitative] summary.
As for GPT-3.5, it stuck to the chain-of-thought format but gave out the wrong answer initially.

However, the issue was patched in June, with the model showing enhancements in terms of its performance.
On the other hand, there was about 40% growth in GPT-3.5s response length.
The answer overlap between their March and June versions was also small for both services."

stated the Stanford Researchers.
They further attributed the disparities to the “drifts of chain-of-thoughts effects.”
Whereas, in June, both models blatantly refused to give a response to the same query.
So they are tweaking gpt to provide same quality answers with less resources and test them a lot.
If they see regressions, they roll back and try something different.
So in their view, it didnt get any dumber, but it did got a lot cheaper.

More benchmarks need to be conducted to study these trends.
Admittedly, the company has consistently pushed new updates to the platform, andseveral improvements can be cited.
This highlights the need to continuously evaluate and assess the behavior of LLMs in production applications.